Foreword: The New #1 Job for AI Engineers
For the past two years, a seismic shift has been quietly reshaping the world of artificial intelligence. It began not with a new algorithm or a faster chip, but with a change in language. On social media and in the private channels of top AI labs, engineers and researchers started to grow dissatisfied with the term “prompt engineering.” While it captured the initial magic of coaxing a Large Language Model (LLM) to perform a task, it felt increasingly inadequate to describe the real work of building intelligent, reliable AI systems.
The breakthrough came when leaders in the field began to converge on a new term. Tobi Lütke, the CEO of Shopify, put it plainly: “I really like the term ‘context engineering’ over prompt engineering. It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.” This wasn’t just a semantic preference; it was a re-framing of the entire challenge. The emphasis moved from the cleverness of a single command to the sophisticated architecture of the information surrounding it.
Andrej Karpathy, one of the most influential minds in AI, amplified this idea, providing the foundational analogy that will guide us through this handbook. He proposed we think of LLMs as a new kind of operating system. In this powerful metaphor, the LLM itself is the Central Processing Unit (CPU)—the core reasoning engine. The context window, that finite space where we provide our information, is its Random Access Memory (RAM)—the model’s active, working memory.
Just as a computer’s OS manages what data moves into RAM for the CPU to process, our job as builders has become to manage the data that flows into the LLM’s context window. Karpathy crystallized the mission: “Context engineering is the delicate art and science of filling the context window with just the right information for the next step.”

This is not a trivial task. The developers at Cognition, creators of the AI agent Devin, have stated that “Context engineering is effectively the number one job of engineers building AI agents.” This handbook is your guide to that number one job. We will move beyond the simple tricks of prompting and into the systematic discipline of building robust information environments for AI. You will learn the four pillars of this new craft: how to write context to external memory, how to select the right information to pull in, how to compress it to its essential core, and how to isolate it to prevent confusion and failure.
Mastering these skills is the difference between building a clever demo and a production-ready system that can reliably handle complex, real-world tasks. Welcome to the art and science of context engineering.
Part 1: The Foundations of Context
Chapter 1: The Evolution from Prompt Engineering to Context Engineering
1.1 What is Prompt Engineering?
In the early days of publicly accessible Large Language Models, the world was captivated by a new form of interaction. For the first time, we could “program” a machine in plain English. This practice was quickly dubbed “prompt engineering.” At its core, prompt engineering is the skill of crafting effective inputs (prompts) to guide an LLM toward a desired output.
Early prompt engineering felt like a mix of art, arcane knowledge, and trial-and-error.[8] A vibrant ecosystem of tips and tricks emerged, often shared on social media and in community forums. These techniques included:
- Assigning a Persona: Telling the model to “Act as a…” or “You are a…” to frame its response style (e.g., “Act as a nutritionist and give me tips about a balanced Mediterranean diet”).
- Zero-Shot, One-Shot, and Few-Shot Prompting: Giving the model a task with no examples (zero-shot), a single example (one-shot), or several examples (few-shot) to demonstrate the desired output format.
- Chain-of-Thought Prompting: Instructing the model to “think step-by-step” to improve its reasoning on complex problems.
- Adding “Magic Phrases”: Speculative tricks like promising a tip for a good answer or using phrases like “take a deep breath” were experimented with to coax better performance.
While these techniques were foundational and remain useful, they primarily address single-turn interactions. The very term “prompt engineering” began to feel limiting, sometimes used derisively to imply it was simply a pretentious name for typing things into a chatbot. The real challenge wasn’t just in the prompt, but in everything that needed to come with it.
1.2 Defining Context Engineering
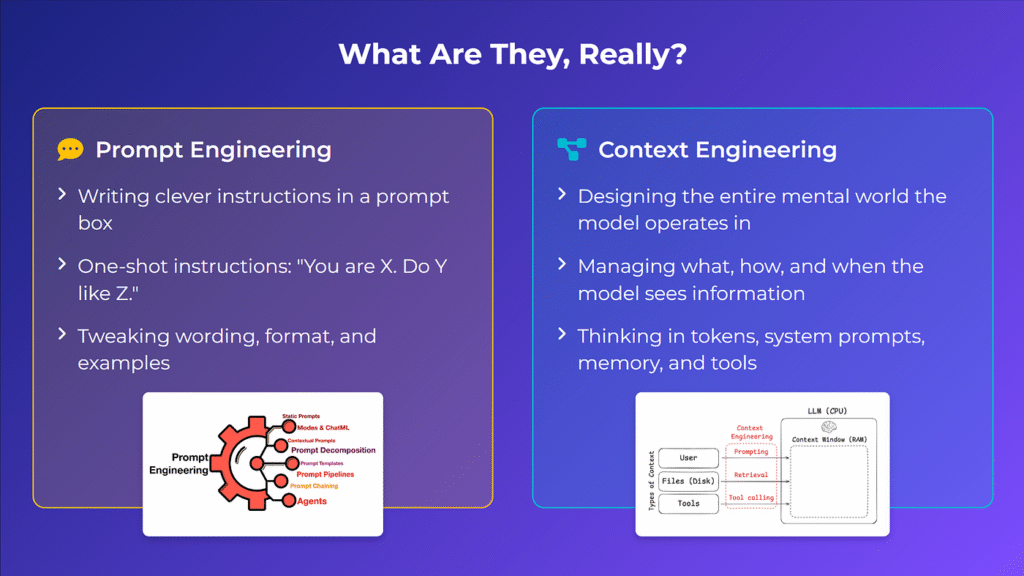
Context engineering encompasses prompt engineering but zooms out to a much wider view. It is a systems approach to managing the entire flow of information into an LLM’s working memory across long and complex tasks. If prompt engineering is writing a single, well-formed command-line instruction, context engineering is designing the entire operating environment in which that command will be executed.
Revisiting Karpathy’s definition, context engineering is “the delicate art and science of filling the context window with just the right information for the next step.” This definition has two crucial parts:
- “Just the right information”: This implies a process of curation and selection. It’s not about dumping as much data as possible into the prompt but about providing the specific, relevant, and necessary pieces of information the model needs to succeed.
- “For the next step”: This highlights the dynamic, multi-turn nature of modern AI applications. In an agentic system that might run for hundreds of steps, the “right information” changes from moment to moment.
Context engineering, therefore, is not about a static prompt. It is the ongoing process of dynamically assembling instructions, examples, retrieved knowledge, and tool feedback into a coherent package for the LLM at every stage of a task. It’s a shift from being a “prompt artist” to an “information architect.”
1.3 Why This Shift is Happening Now
The pivot from prompt to context engineering has been driven by a confluence of three major trends in AI development:
- The Rise of Agentic Systems: Applications are moving beyond simple question-and-answer bots. Modern AI “agents” can perform multi-step tasks, use external tools like APIs and code interpreters, and sustain long interactions to solve complex problems. This agentic behavior means the context from previous steps (like the output of a tool) must be managed and fed into subsequent steps, creating a complex information flow.
- The Explosion of Context Windows: The “working memory” of LLMs has grown at a staggering rate, arguably a new Moore’s Law for AI. This expansion has been dramatic:
- ~2022: Models like GPT-3 had context windows of around 2,048 tokens.2023: The barrier was shattered with models supporting 100,000 tokens.2024 and beyond: The frontier pushed into the millions, with models like Google’s Gemini 1.5 Pro handling up to 2 million tokens.
- The “God is Hungry for Context” Principle: As models become more powerful, their ability to leverage large amounts of well-structured context increases. Simply giving a more capable model more relevant data can unlock significantly better performance. However, the inverse is also true. Giving it a huge volume of irrelevant data can degrade its performance. The engineering challenge is to feed the model’s hunger with high-quality, relevant information.
This combination of more complex tasks, vastly larger memory, and more capable models has made context management the central, defining challenge of building state-of-the-art AI applications.
Chapter 2: The Anatomy of the Context Window
2.1 The Context Window as Working Memory (RAM)
To effectively engineer context, we must first understand the nature of the space we are working in. The context window is the total span of tokens that an LLM can access and process at one time. It includes both the input we provide and the output the model generates. Thinking of it as the LLM’s RAM is a robust analogy that reveals its key properties and limitations.
- Limited Capacity: Just like RAM, the context window has a finite size. While it has expanded dramatically, it is not infinite. Once you exceed the limit, the model loses access to the earliest information—a phenomenon sometimes called “anterograde amnesia”—leading to errors and loss of coherence.
- Computational Cost: The cost of using the context window is not just about capacity. In standard Transformer architectures, the computational requirement grows quadratically with the length of the context. Doubling the context length can quadruple the processing time and memory needed, making very large contexts expensive in terms of both latency and financial cost. Token-based pricing models mean that every piece of information you put into the context has a direct monetary cost.
- I/O Bottleneck: Getting information into and out of the context window is the primary interaction point with the LLM. Every instruction, every piece of data, and every tool output must pass through this channel. Managing this I/O efficiently is key to performance.
2.2 The Five Core Types of Context
The information we place into this “RAM” can be categorized into several distinct types. A successful context engineer knows how to blend these ingredients to create the perfect recipe for the task at hand. The primary types are:
- Instructions: This is the most direct form of context, telling the model what to do. It includes the user’s primary query, the system prompt that sets the model’s persona and high-level directives, and rules for output formatting.
- Knowledge: This is external information the model needs to consult to answer a query accurately. This is the domain of Retrieval-Augmented Generation (RAG), where relevant documents, database entries, or web search results are fetched and placed into the context to ground the model’s response in facts.
- Tool-Related Context: For AI agents, tools are a critical source of context. This includes the descriptions of available tools (so the model knows what it can do) and, crucially, the output or feedback from executing those tools (e.g., an API response, code execution result, or error message).
- Examples (Few-shot Learning): Providing concrete examples of the desired input/output behavior is one of the most powerful ways to guide a model. These “few-shot examples” act as a form of “in-context training,” showing the model the pattern to follow without requiring a full fine-tuning process.
- Memory: This refers to information from the history of the interaction. It can be a verbatim transcript of the last few turns of a conversation or a synthesized summary of past interactions to remind the model of key decisions, user preferences, or established facts from earlier in the session.
2.3 Common Modes of Context Failure
A larger context window is not a silver bullet. In fact, as the context grows, so does the potential for error. The most well-known challenge is the “Needle in a Haystack” problem. This refers to a model’s decreasing ability to find a specific piece of information (the “needle”) as the amount of surrounding, irrelevant text (the “haystack”) increases. Research and practical experience have shown that even the most advanced models can struggle to retrieve information buried deep within a long context.
This core challenge leads to several specific modes of failure:
- Context Poisoning: When incorrect or hallucinated information is introduced into the context (perhaps from a previous, flawed model generation), it can “poison” subsequent steps, leading the agent down a wrong path.
- Distraction / Semantic Masking: Similar to the needle-in-a-haystack issue, a model can be distracted by irrelevant but semantically similar information in the context, causing it to overlook the correct information or generate a response that is off-topic.
- Curation Failure: This happens when the system fails to retrieve the necessary knowledge or tool outputs and place them into the context. The model fails not because it reasoned incorrectly, but because it was never given the information it needed to succeed.
- Clash: When conflicting information is present in the context (e.g., two different documents give two different answers), the model may struggle to resolve the ambiguity, leading to a hedged, incorrect, or nonsensical answer.
Understanding these failure modes is the first step toward engineering solutions. The strategies we will explore in Part 2 are all designed to mitigate these risks by ensuring the context window is not just large, but clean, relevant, and focused.
Conclusion: From Raw Potential to Engineered Reliability
We stand at a critical inflection point in the development of artificial intelligence. The initial era, defined by the magic of “prompting” and the thrill of seeing a machine understand our words, is giving way to a more mature, demanding phase of engineering. We have moved beyond simply demonstrating an LLM’s potential; our task now is to build systems that can realize that potential reliably, scalably, and safely.
The battleground where this transition will be won or lost is the context window. It is the sole gateway to the LLM’s reasoning capabilities—a powerful but perilous resource. As we have seen, filling this space haphazardly is a recipe for failure. An unmanaged context becomes a noisy, confusing environment where vital information is buried, conflicting data causes paralysis, and the agent’s focus drifts.
Understanding this challenge—the anatomy of the context window, the ingredients that fill it, and the ways it can fail—is the foundational knowledge for every modern AI builder. But knowledge alone is not enough. The path forward requires a new toolkit of strategies designed specifically for this environment.
Having established the “what” and the “why,” we are now prepared to explore the “how.” In the chapters that follow, we will deconstruct the four fundamental pillars of practical context engineering: Writing context to external memory to grant our agents persistence; Selecting only the most relevant information to sharpen their focus; Compressing that information to its essential core to manage costs and complexity; and Isolating it into clean, partitioned spaces to prevent interference and enable sophisticated, multi-part reasoning.
Mastering these pillars is the key to transforming AI from a promising but often brittle technology into a robust and reliable partner, capable of tackling real-world complexity.
The journey from prompt artist to information architect begins now.